参考 Huang. et.el., 2021 Supplementary Fig. 1
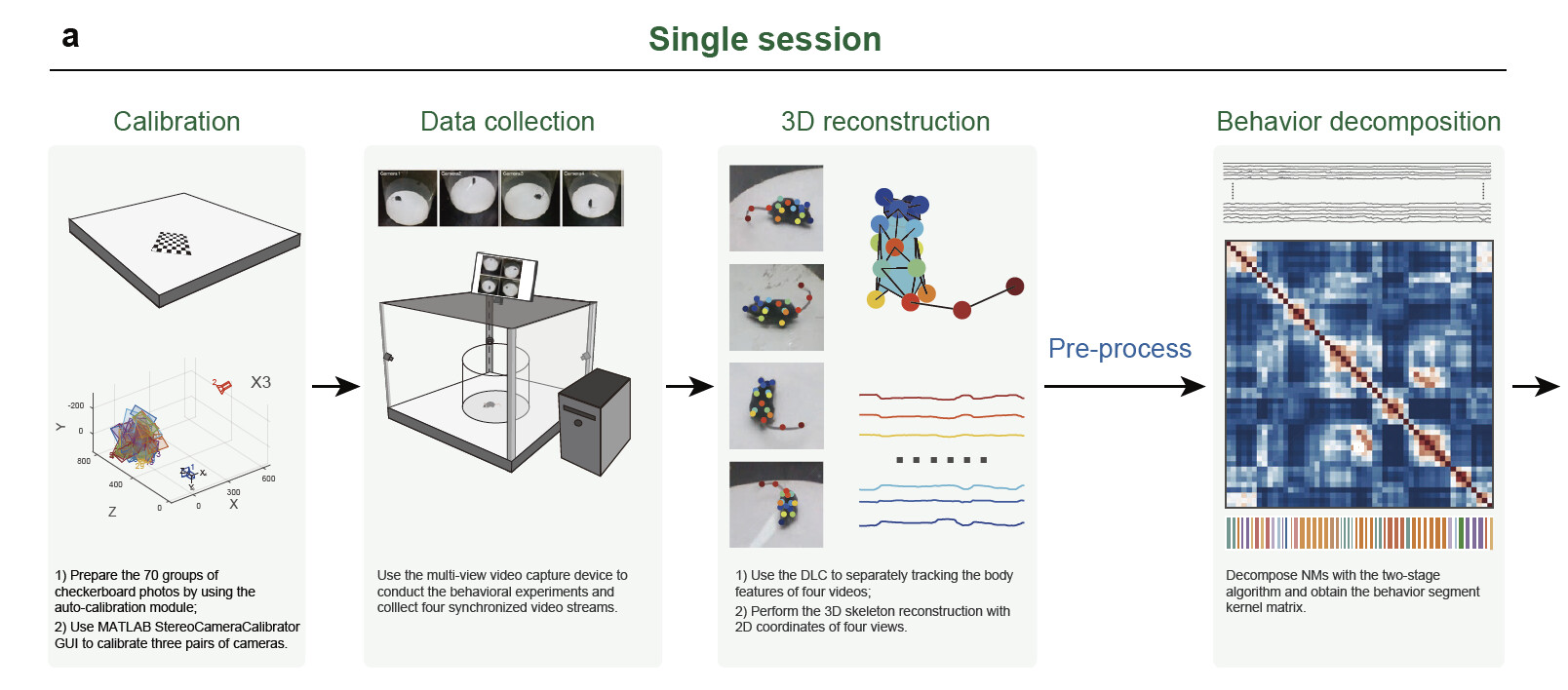
Supplementary Fig. 1 | The workflow of the hierarchical 3D-motion learning framework. a Fourmain steps for a single experimental session: 1) Calibration. Using the auto-calibration module to quickly prepare 70 groups of checkerboard images from various angles and positions for calibration and using the MATLAB StereoCameraCalibrator GUI to calculate the calibration parameters of the three pairs ofcameras. This step is necessary only when the calibration parameters are unknown, or the cameras havebeen moved. 2) Data collection (related to Supplementary Methods Animals, behavioral experimentsand behavioral data collection). Setting up the behavioral apparatus and preparing the animal and thenusing the multi-view video capture device to collect the synchronous behavioral videos. 3)3Dreconstruction (related to Supplementary Methods 3D pose reconstruction). Using the DLC pre-trained model to predict the animal’s 16 body-part 2D coordinates from the four separate videos, then performing the 3D skeleton reconstruction with the 2D coordinates from four views to obtain the animal’s postural time-series.
其他参考
1. Cao. et.al., 2023
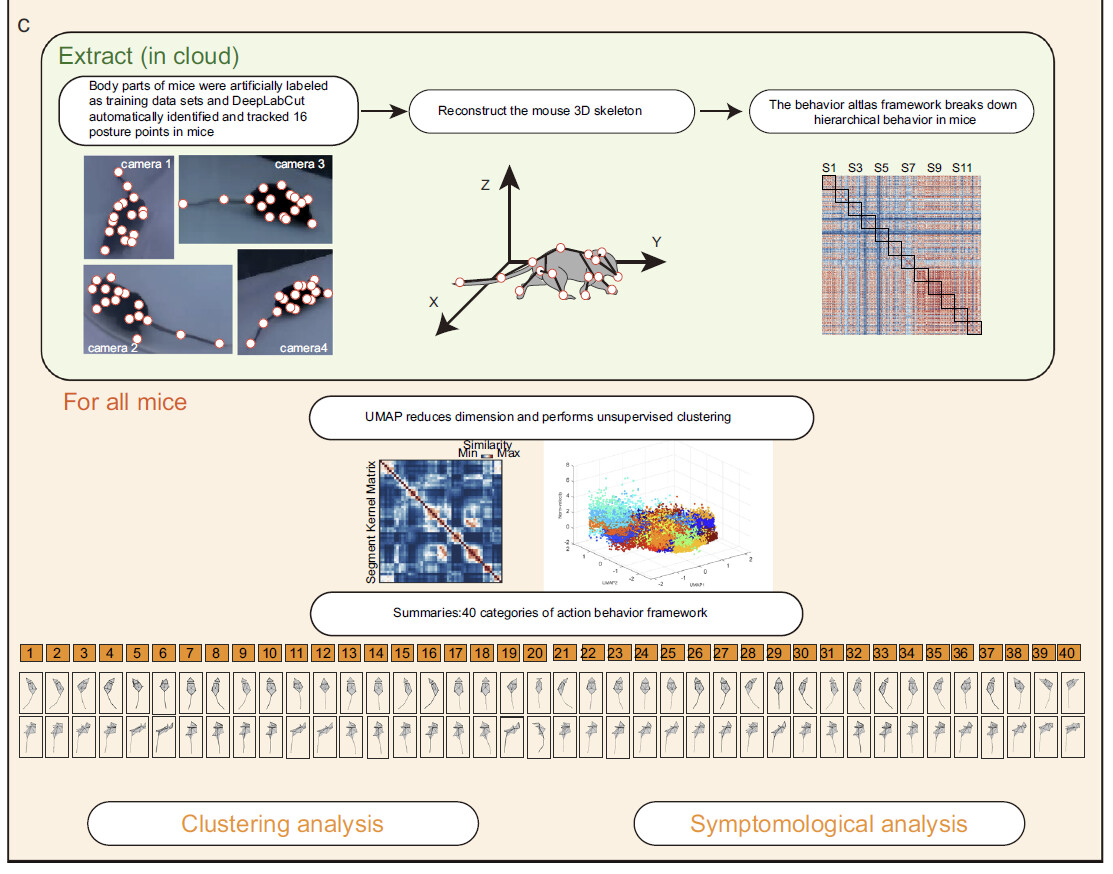
All processes are described in Fig. 1c. Pipeline of mouse behaviour recording and analysis via 3D-motion learning framework. Top: 3 steps for single mouse 3D body reconstruction and movement segmentation. First, using pre-trained DeepLabCut model to track the 2D coordinates of 16 body parts from each camera view; second, reconstructing the mouse 3D skeleton by fusing four views 2D coordinates;
2. Tseng. et.al., 2023
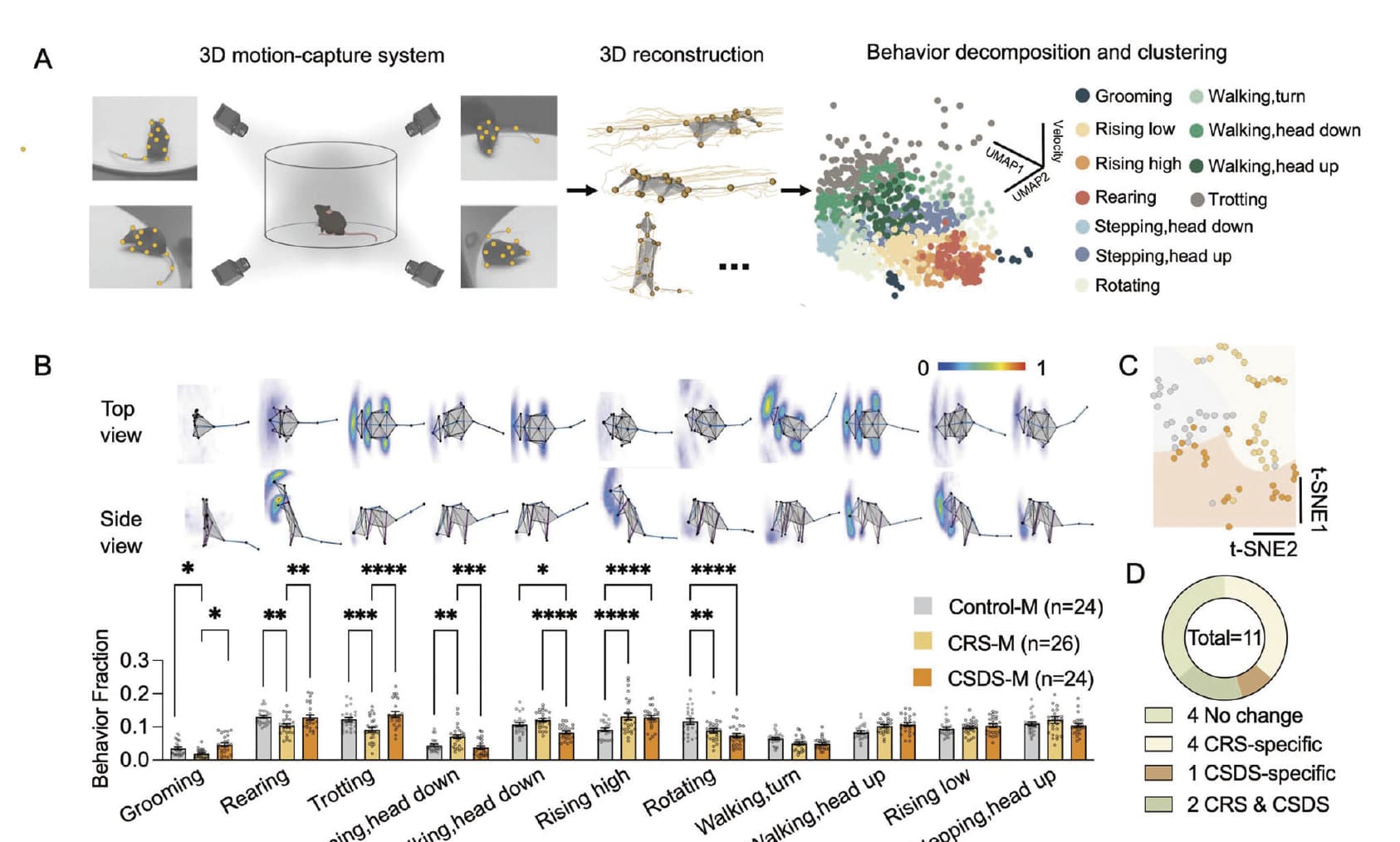
3D motion-capture system and behavior decomposition framework
The setup was similar to our previous study [22]. Briefly, cameras on the four sides of the apparatus synchronously record spontaneous behaviors of mice, then an ML-based method was used to automatically identify the behavioral phenotypes of mice. Unsupervised behavioral movement clusters were further recognized by supervised classification. Behavior fractions were calculated as the total time performing one type of behavior movement divided by the total time of all behavior movements, and a behavioral transition represents one type of behavior movement translated to another. More details are provided in the supplementary information.
3. Liu. et.al., 2022
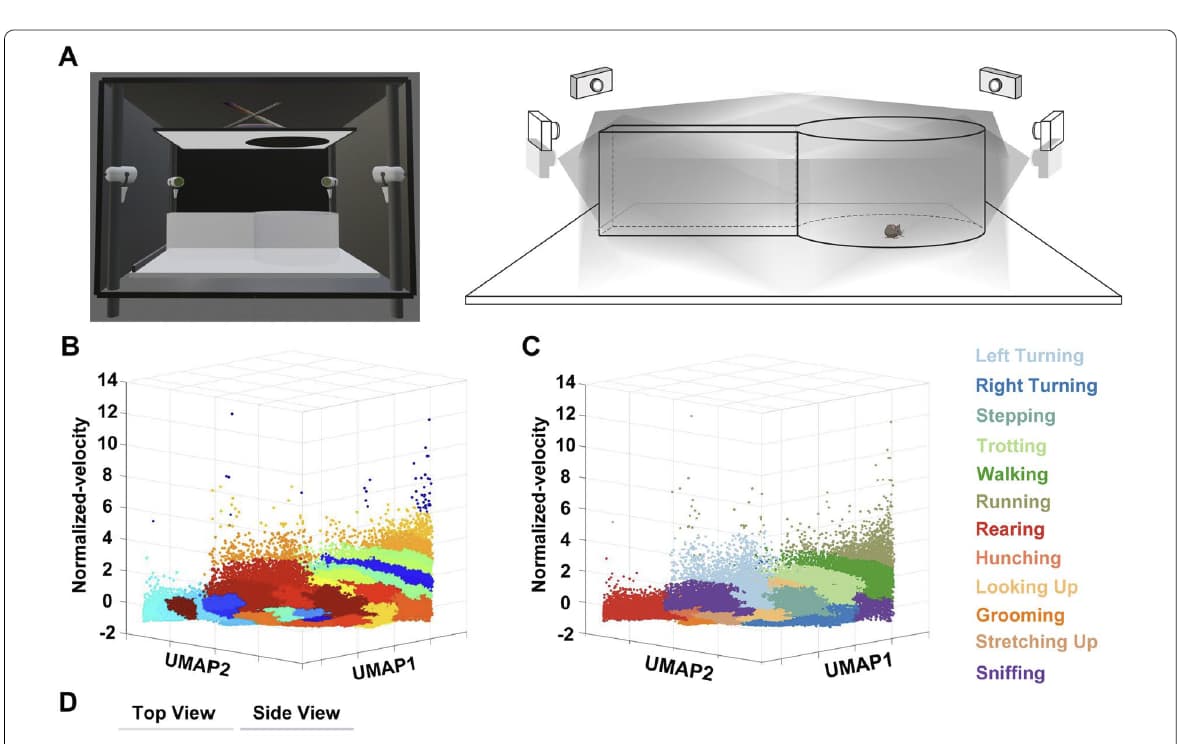
The 3D-motion multi-layered framework adapted for the visually-evoked defensive behavior paradigm. A Schematic showing the experimental setup (left) and schematic diagram of the behavioral recording arena with four synchronized cameras (right). B Spatiotemporal feature space of behavioral components with unsupervised learning.