一、导言
Python 之所以被赞誉为功能强大的编程语言,其众多实用且可靠的第三方库功不可没。其中,Numpy(由 “Number” 与 “Python” 组合而成)堪称助力 Python 声名远扬、地位崇高的关键第三方库之一。
二、为什么要用Numpy
- 当需要对数据进行批量处理时。
- 在机器学习、人工智能等领域,面对海量数据的运算处理需求。
- 在编写游戏中物体的运行逻辑过程中,矩阵和向量运算频繁出现的场景。
- 在机器人模拟环境里,背后的环境反馈信息皆依赖批量数据运算得出。
- 只要涉及数据统计的任何情况(例如在完成爬虫信息抓取之后)。
- 在绘制图表之前,需要对数据开展一轮批量处理工作时。
- 等等。
三、如何安装Numpy
1.打开cmd
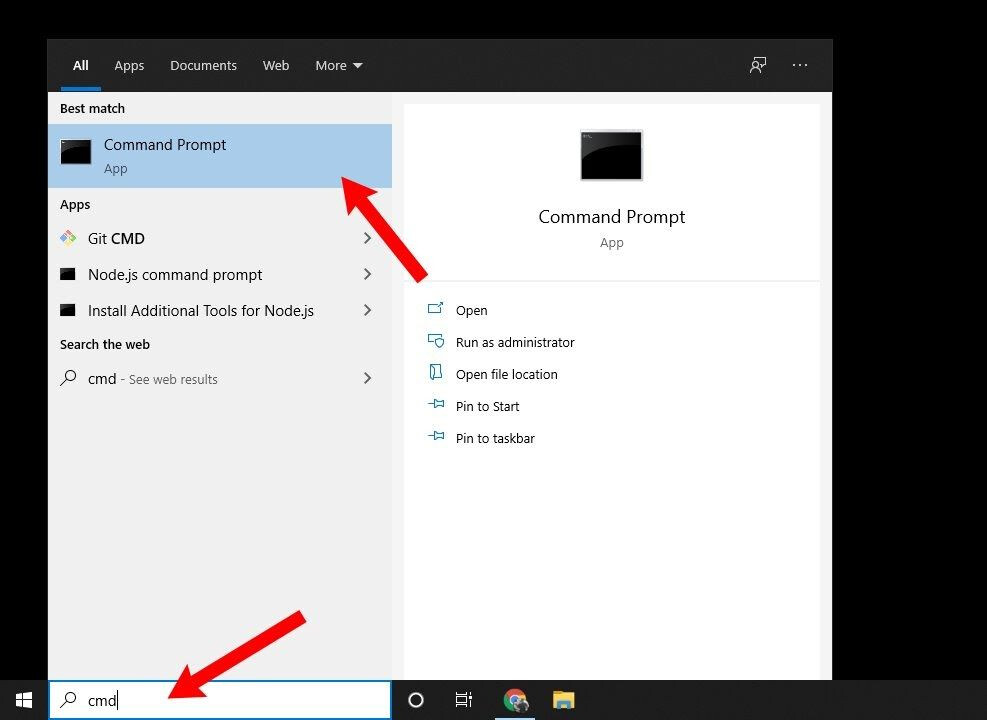
2.我们可以使用pip命令直接安装numpy(这样的话默认把numpy安装在base环境中)
pip 的方法很简单,你只需要在终端里面输入下面这样:
pip install numpy
如果执行下面这句话,没有任何提示,则说明安装好了。
python -c "import numpy"
如果提示下面这样的信息,就意味着安装失败。
Traceback (most recent call last):
File "<string>", line 1, in <module>
ModuleNotFoundError: No module named 'numpy'
3. 你也可以使用conda来创建虚拟环境,在虚拟环境中来安装numpy
# 创建 Python 环境
conda create -n numpy_study python=3.10 -y
# 激活环境
conda active numpy_study
# 在这个 my-env 的Python环境中安装 numpy
conda install numpy
# 或者直接用 pip 安装也能用
pip install numpy
同样的,如果执行下面这句话,没有任何提示,则说明安装好了。
python -c "import numpy"
如果提示下面这样的信息,就意味着安装失败。
Traceback (most recent call last):
File "<string>", line 1, in <module>
ModuleNotFoundError: No module named 'numpy'
四、第一行Numpy代码
Numpy界的hello world。
import numpy as np
print(np.array([1,1,2]))
五、Numpy和List的区别
Numpy 的核心是 ndarray 对象(n-dimensional array,N维数组),它与 Python 的原生 list 相比,特别在处理大规模数据的批量计算时,速度要快得多。这是因为 Numpy 的底层是用 C 语言编写的,并且它能进行向量化运算(vectorized operations),避免了 Python 循环的开销。
import time
import numpy as np
n_elements = 100000 # 增加数据量以更明显地看到差异
n_loops = 100
# --- Python list 性能测试 ---
t0 = time.time()
# 创建 python list
l = list(range(n_elements))
for _ in range(n_loops):
for i in range(len(l)):
l[i] += 1
t1 = time.time()
# --- Numpy array 性能测试 ---
# 创建 numpy array
a = np.arange(n_elements) # 使用 np.arange 更高效地创建序列数组
for _ in range(n_loops):
a += 1 # Numpy 的向量化操作
t2 = time.time()
print(f"Python list spend {t1-t0:.3f}s")
print(f"Numpy array spend {t2-t1:.3f}s")
# 你会看到 Numpy 的运算速度明显快于纯 Python list 的循环操作
Numpy 数组中的所有元素必须是相同的数据类型,这使得存储和计算更加高效。而 Python 列表可以包含不同类型的元素。
六、Numpy中的维度 (Dimensions)
Numpy 数组可以有多个维度。ndarray 对象有一个 ndim 属性,表示数组的维度数量(也称为“轴”的数量)。
示例一:一维数组 (1-D Array / Vector)
import numpy as np
# 创建一维数组
data = np.array([5, 10, 12, 6])
print("数据:", data)
print("维度数量:", data.ndim)
# 输出:
# 数据: [ 5 10 12 6]
# 维度数量: 1
示例二:二维数组 (2-D Array / Matrix)
import numpy as np
# 创建二维数组
data = np.array([
[5, 10, 12, 6],
[5.1, 8.2, 11, 6.3],
[4.4, 9.1, 10, 6.6]
])
print("数据:\n", data)
print("维度数量:", data.ndim)
# 输出:
# 数据:
# [[ 5. 10. 12. 6. ]
# [ 5.1 8.2 11. 6.3]
# [ 4.4 9.1 10. 6.6]]
# 维度数量: 2
示例三:三维或更高维数组 (N-D Array / Tensor)
import numpy as np
# 创建三维数组
data = np.array([
[[1, 2], [3, 4]], # 第一个 2x2 矩阵
[[5, 6], [7, 8]] # 第二个 2x2 矩阵
])
print("数据:\n", data)
print("维度数量:", data.ndim)
# 输出:
# 数据:
# [[[1 2]
# [3 4]]
#
# [[5 6]
# [7 8]]]
# 维度数量: 3
七、Numpy ndarray 的重要属性
除了 ndim,ndarray 还有一些其他重要的属性:
shape: 返回一个元组(tuple),表示数组在每个维度上的大小。对于矩阵,就是 (行数, 列数)。
size: 返回数组中元素的总数,等于 shape 元组中所有元素的乘积。
dtype: 返回描述数组中元素类型的数据类型对象(如 int64, float64, bool 等)。
import numpy as np
#创建一个二维数组
arr = np.array([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
print("数组:\n", arr)
print("维度数量 (ndim):", arr.ndim)
print("形状 (shape):", arr.shape)
print("总元素数量 (size):", arr.size)
print("数据类型 (dtype):", arr.dtype)
#输出:
#数组:
#[[1. 2. 3.]
#[4. 5. 6.]]
#维度数量 (ndim): 2
#形状 (shape): (2, 3)
#总元素数量 (size): 6
#数据类型 (dtype): float64
八、Numpy 数据选取 (Indexing and Slicing)
从数组中选取元素或子数组是常见的操作。
索引 (Indexing)
类似于 Python 列表,你可以使用方括号 [] 和索引来访问单个元素。对于多维数组,使用逗号分隔不同维度的索引。
import numpy as np
# 一维数组索引
arr1d = np.array([10, 11, 12, 13, 14])
print("第一个元素:", arr1d[0]) # 输出: 10
print("最后一个元素:", arr1d[-1]) # 输出: 14
# 二维数组索引
arr2d = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
print("二维数组:\n", arr2d)
# 选取第 1 行(索引为0),第 2 列(索引为1)的元素
print("arr2d[0, 1]:", arr2d[0, 1]) # 输出: 2
# 也可以分步索引
print("arr2d[0][1]:", arr2d[0][1]) # 输出: 2 (效果相同,但效率稍低)
# 选取第 3 行(索引为2),第 3 列(索引为2)的元素
print("arr2d[2, 2]:", arr2d[2, 2]) # 输出: 9
切片 (Slicing)
切片用于选取数组的一个子集(子数组)。其语法是 start:stop:step,其中 stop 索引对应的元素不包含在内。
import numpy as np
# 一维数组切片
arr1d = np.array([10, 11, 12, 13, 14, 15])
print("索引1到3的元素:", arr1d[1:4]) # 输出: [11 12 13]
print("前3个元素:", arr1d[:3]) # 输出: [10 11 12]
print("从索引2开始的所有元素:", arr1d[2:]) # 输出: [12 13 14 15]
print("步长为2选取:", arr1d[::2]) # 输出: [10 12 14]
# 二维数组切片
arr2d = np.array([[1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12]])
print("二维数组:\n", arr2d)
# 选取前 2 行(索引0和1),从第 2 列(索引1)到第 3 列(索引2)
# 结果是一个 2x2 的数组
sub_arr = arr2d[0:2, 1:3]
print("子数组 arr2d[0:2, 1:3]:\n", sub_arr)
# 输出:
# [[2 3]
# [6 7]]
# 只选取特定行或列
print("选取第一行:", arr2d[0, :]) # 或 arr2d[0]
# 输出: [1 2 3 4]
print("选取第二列:", arr2d[:, 1])
# 输出: [ 2 6 10]
注意: Numpy 切片返回的是原始数组的视图 (view),而不是副本 (copy)。这意味着修改视图会影响原始数组。如果需要副本,可以使用 .copy() 方法。
arr = np.array([1, 2, 3, 4])
slice_view = arr[1:3]
print("Original array:", arr) # [1 2 3 4]
print("Slice view:", slice_view) # [2 3]
slice_view[0] = 99 # 修改视图
print("Slice view after modification:", slice_view) # [99 3]
print("Original array after modification:", arr) # [ 1 99 3 4] <-- 原始数组也被改变了
# 如果需要副本
slice_copy = arr[1:3].copy()
slice_copy[0] = 100
print("Slice copy:", slice_copy) # [100 3]
print("Original array:", arr) # [ 1 99 3 4] <-- 原始数组不受影响
布尔索引 (Boolean Indexing)
我们可以使用一个布尔数组来选取元素。布尔数组的形状通常与原数组相同,其中 True 对应的位置的元素会被选中。这在根据条件筛选数据时非常有用。
import numpy as np
arr = np.array([[1, 2], [3, 4], [5, 6]])
print("数组:\n", arr)
# 创建一个布尔条件
condition = arr > 3
print("条件 (arr > 3):\n", condition)
# 输出:
# [[False False]
# [False True]
# [ True True]]
# 使用布尔条件进行索引
print("大于3的元素:", arr[condition]) # 输出: [4 5 6] (返回一个一维数组)
# 也可以直接在索引中写条件
print("偶数元素:", arr[arr % 2 == 0]) # 输出: [2 4 6]
九、Numpy 基本运算
Numpy 允许对整个数组执行快速的运算。
算术运算 (Element-wise)
标准的算术运算符 (+, -, *, /, ** 等) 默认进行元素级 (element-wise) 运算。即运算符作用于两个数组中对应位置的元素。
import numpy as np
a = np.array([1, 2, 3, 4])
b = np.array([10, 20, 30, 40])
# 数组与数组运算 (要求形状兼容,通常是相同形状)
print("a + b =", a + b) # 元素级加法: [1+10, 2+20, 3+30, 4+40] -> 输出: [11 22 33 44]
print("b - a =", b - a) # 元素级减法: [10-1, 20-2, 30-3, 40-4] -> 输出: [ 9 18 27 36]
print("a * b =", a * b) # 元素级乘法: [1*10, 2*20, 3*30, 4*40] -> 输出: [ 10 40 90 160]
print("b / a =", b / a) # 元素级除法: [10/1, 20/2, 30/3, 40/4] -> 输出: [10. 10. 10. 10.]
print("a ** 2 =", a ** 2) # 元素级幂运算: [1^2, 2^2, 3^2, 4^2] -> 输出: [ 1 4 9 16]
# 数组与标量运算 (Broadcasting)
# 标量会自动扩展 (broadcast) 到数组的形状进行元素级运算
print("a + 5 =", a + 5) # 输出: [6 7 8 9]
print("a * 2 =", a * 2) # 输出: [2 4 6 8]
矩阵乘法 (Matrix Multiplication / Dot Product)
对于二维数组(矩阵),标准的数学矩阵乘法使用 @ 运算符 (Python 3.5+) 或 np.dot() 函数/方法。这与元素级乘法 * 不同。
进行矩阵乘法 A@B 时,第一个矩阵 A 的列数必须等于第二个矩阵 B 的行数。如果 A 是 (m * n) 矩阵,B 是 (n * p) 矩阵,则结果 C = A @ B 是 (m * p) 矩阵。
import numpy as np
mat_a = np.array([[1, 2], [3, 4]]) # Shape (2, 2)
mat_b = np.array([[5, 6], [7, 8]]) # Shape (2, 2)
mat_c = np.array([[1, 2, 3], [4, 5, 6]]) # Shape (2, 3)
print("Matrix A:\n", mat_a)
print("Matrix B:\n", mat_b)
print("Matrix C:\n", mat_c)
# 使用 @ 运算符进行矩阵乘法 (A @ B)
result_at = mat_a @ mat_b
print("A @ B:\n", result_at)
# 输出:
# [[1*5+2*7, 1*6+2*8],
# [3*5+4*7, 3*6+4*8]]
# -> [[19 22],
# [43 50]]
# 使用 np.dot() 函数进行矩阵乘法 (A @ C)
# A(2x2) @ C(2x3) -> Result(2x3)
result_dot = np.dot(mat_a, mat_c)
print("np.dot(A, C):\n", result_dot)
# 输出:
# [[1*1+2*4, 1*2+2*5, 1*3+2*6],
# [3*1+4*4, 3*2+4*5, 3*3+4*6]]
# -> [[ 9 12 15],
# [19 26 33]]
# 也可以使用 ndarray 对象的 dot 方法
result_method = mat_a.dot(mat_b)
print("A.dot(B):\n", result_method) # 与 A @ B 结果相同
元素级乘法 vs 矩阵乘法
务必区分元素级乘法 (*) 和矩阵乘法 (@ 或 np.dot())。
import numpy as np
mat_a = np.array([[1, 2], [3, 4]])
mat_b = np.array([[5, 6], [7, 8]])
print("Matrix A:\n", mat_a)
print("Matrix B:\n", mat_b)
# 元素级乘法
element_wise_mult = mat_a * mat_b
print("元素级乘法 (A * B):\n", element_wise_mult)
# 输出:
# [[1*5, 2*6],
# [3*7, 4*8]]
# -> [[ 5 12],
# [21 32]]
# 矩阵乘法
matrix_mult = mat_a @ mat_b
print("矩阵乘法 (A @ B):\n", matrix_mult)
# 输出:
# [[1*5+2*7, 1*6+2*8],
# [3*5+4*7, 3*6+4*8]]
# -> [[19 22],
# [43 50]]
通用函数 (Universal Functions - ufuncs)
Numpy 提供了许多通用函数,它们也是对数组进行元素级操作的函数。
import numpy as np
arr = np.array([0, np.pi/2, np.pi])
print("数组:", arr)
# 三角函数
print("sin(arr):", np.sin(arr)) # [0.0000000e+00 1.0000000e+00 1.2246468e-16] (接近0)
# 指数和对数
print("exp(arr):", np.exp(arr)) # [ 1. 4.81047738 23.14069263]
print("sqrt(arr):", np.sqrt(np.array([1, 4, 9]))) # [1. 2. 3.]
聚合函数 (Aggregate Functions)
这些函数对数组中的数据进行汇总计算。
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("数组:\n", arr)
print("所有元素求和:", arr.sum()) # 或 np.sum(arr) -> 输出: 21
print("所有元素均值:", arr.mean()) # 或 np.mean(arr) -> 输出: 3.5
print("最大值:", arr.max()) # 或 np.max(arr) -> 输出: 6
print("最小值:", arr.min()) # 或 np.min(arr) -> 输出: 1
print("标准差:", arr.std()) # 或 np.std(arr) -> 输出: 1.7078...
# 沿指定轴计算
# axis=0: 沿着行的方向操作(计算每一列的和)
print("按列求和 (axis=0):", arr.sum(axis=0)) # 输出: [5 7 9]
# axis=1: 沿着列的方向操作(计算每一行的和)
print("按行求和 (axis=1):", arr.sum(axis=1)) # 输出: [ 6 15]
十、Numpy 数组变形 (Array Transformation)
改变数组的形状或组合/拆分数组是常见的需求。
改变形状 (Reshaping)
import numpy as np
a = np.arange(12) # [ 0 1 2 3 4 5 6 7 8 9 10 11]
print("原始数组:", a)
# 重塑为 3x4 矩阵
b = a.reshape(3, 4)
print("重塑为 3x4:\n", b)
# 输出:
# [[ 0 1 2 3]
# [ 4 5 6 7]
# [ 8 9 10 11]]
# 重塑为 4x3 矩阵
c = a.reshape(4, 3)
print("重塑为 4x3:\n", c)
# 输出:
# [[ 0 1 2]
# [ 3 4 5]
# [ 6 7 8]
# [ 9 10 11]]
# 可以让 Numpy 自动计算一个维度的大小,用 -1 表示
d = a.reshape(6, -1) # 自动计算为 6x2
print("重塑为 6x(-1):\n", d)
# 输出:
# [[ 0 1]
# [ 2 3]
# [ 4 5]
# [ 6 7]
# [ 8 9]
# [10 11]]
# 注意:reshape 通常返回视图,但如果内存不连续可能返回副本。
转置 (Transposing)
转置操作会交换数组的轴。对于二维数组,就是行列互换。可以使用 .T 属性或 np.transpose() 函数。
import numpy as np
arr = np.array([[1, 2, 3], [4, 5, 6]])
print("原始数组 (2x3):\n", arr)
print("形状:", arr.shape) # (2, 3)
transposed_arr = arr.T # 使用 .T 属性
# transposed_arr = np.transpose(arr) # 使用函数
print("转置后数组 (3x2):\n", transposed_arr)
print("形状:", transposed_arr.shape) # (3, 2)
# 输出:
# [[1 4]
# [2 5]
# [3 6]]
数组连接与分割 (Stacking and Splitting)
可以将多个数组按指定轴连接起来,或者将一个数组分割成多个子数组。
连接 (Concatenation/Stacking)
np.concatenate((arr1, arr2, ...), axis=0): 沿指定轴连接数组。axis=0 是默认值,表示垂直连接(增加行数)。axis=1 表示水平连接(增加列数)。
np.vstack((arr1, arr2)): 垂直堆叠数组(等同于 concatenate axis=0)。
np.hstack((arr1, arr2)): 水平堆叠数组(等同于 concatenate axis=1)。
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6]]) # 注意 b 的形状是 (1, 2)
# 垂直连接 (沿 axis=0)
c = np.concatenate((a, b), axis=0)
print("垂直连接 (concatenate axis=0):\n", c)
# 或使用 vstack
c_vstack = np.vstack((a, b))
print("垂直连接 (vstack):\n", c_vstack)
# 输出:
# [[1 2]
# [3 4]
# [5 6]]
# 水平连接 (沿 axis=1)
# 需要确保连接的维度匹配,这里需要将 b 转置或创建合适的数组
d = np.array([[5], [7]]) # 创建一个 (2, 1) 的数组
e = np.concatenate((a, d), axis=1)
print("水平连接 (concatenate axis=1):\n", e)
# 或使用 hstack (需要 d 的形状是 (2, 1) 或者 a, d 都是一维)
e_hstack = np.hstack((a, d))
print("水平连接 (hstack):\n", e_hstack)
# 输出:
# [[1 2 5]
# [3 4 7]]
分割 (Splitting)
np.split(arr, indices_or_sections, axis=0): 将数组沿指定轴分割。可以提供一个整数 N,将数组平均分割成 N 份;或者提供一个索引列表,在这些索引处进行分割。
np.vsplit(arr, indices_or_sections): 垂直分割(按行分割,等同于 split axis=0)。
np.hsplit(arr, indices_or_sections): 水平分割(按列分割,等同于 split axis=1)。
import numpy as np
arr = np.arange(16).reshape((4, 4))
print("原始数组:\n", arr)
# 水平分割成 2 个相等的部分
left, right = np.hsplit(arr, 2)
print("水平分割 (左):\n", left)
print("水平分割 (右):\n", right)
# 垂直分割,在第1行和第3行之后分割
top, middle, bottom = np.vsplit(arr, [1, 3]) # 分割点为索引 1 和 3
print("垂直分割 (上):\n", top)
print("垂直分割 (中):\n", middle)
print("垂直分割 (下):\n", bottom)
十一、Numpy 数据存取 (Saving and Loading Data)
Numpy 可以方便地将数组保存到磁盘以及从磁盘加载数组。
二进制格式 (.npy, .npz)
这是 Numpy 原生的、高效的二进制格式。
np.save('filename.npy', arr): 将单个数组保存到 .npy 文件。
np.savez('filename.npz', name1=arr1, name2=arr2, ...): 将多个数组保存到未压缩的 .npz 文件。加载时可以通过名称访问。
loaded_arr = np.load('filename.npy'): 加载 .npy 文件。
data = np.load('filename.npz'): 加载 .npz 文件,返回一个类似字典的对象,可以通过 data['name1'] 访问数组。
import numpy as np
# 创建数据
arr1 = np.arange(10)
arr2 = np.random.rand(2, 3) # 2x3 的随机数组
# 保存单个数组
np.save('my_array.npy', arr1)
# 加载单个数组
loaded_arr1 = np.load('my_array.npy')
print("Loaded arr1:", loaded_arr1)
# 保存多个数组
np.savez('my_arrays.npz', first=arr1, second=arr2)
# 加载多个数组
data = np.load('my_arrays.npz')
print("Loaded arr1 from npz:", data['first'])
print("Loaded arr2 from npz:\n", data['second'])
data.close() # 关闭文件
文本格式 (.txt, .csv)
可以将数组保存为纯文本文件,例如 CSV 格式,便于与其他软件(如电子表格)交互。
np.savetxt('filename.txt', arr, delimiter=',', fmt='%.4f'): 将数组保存为文本文件。delimiter: 分隔符(如 , 用于 CSV)。fmt: 输出格式(如 '%.4f' 表示保留4位小数的浮点数)。
loaded_arr = np.loadtxt('filename.txt', delimiter=',', dtype=np.float64): 从文本文件加载数据。delimiter: 读取时使用的分隔符。dtype: 指定加载的数据类型。
import numpy as np
arr = np.arange(12).reshape(3, 4) * 0.5
print("Array to save:\n", arr)
# 保存为 CSV 文件,保留两位小数
np.savetxt('my_data.csv', arr, delimiter=',', fmt='%.2f', header='col1,col2,col3,col4', comments='')
# 从 CSV 文件加载
loaded_data = np.loadtxt('my_data.csv', delimiter=',', dtype=np.float32) # 可以指定不同类型
print("Loaded data from csv:\n", loaded_data)
到这里,我们已经掌握了 Numpy 的核心概念和常用操作。