【CVPR 2025 最佳论文 VGGT:视觉几何感知的一次革命】
【CVPR 2025 最佳论文 VGGT:视觉几何感知的一次革命】
代码仓库 ![]()
![]() vggt
vggt
论文链接
![]() VGGT: Visual Geometry Grounded Transformer
VGGT: Visual Geometry Grounded Transformer
快速演示
![]() Hugging face 快速演示
Hugging face 快速演示
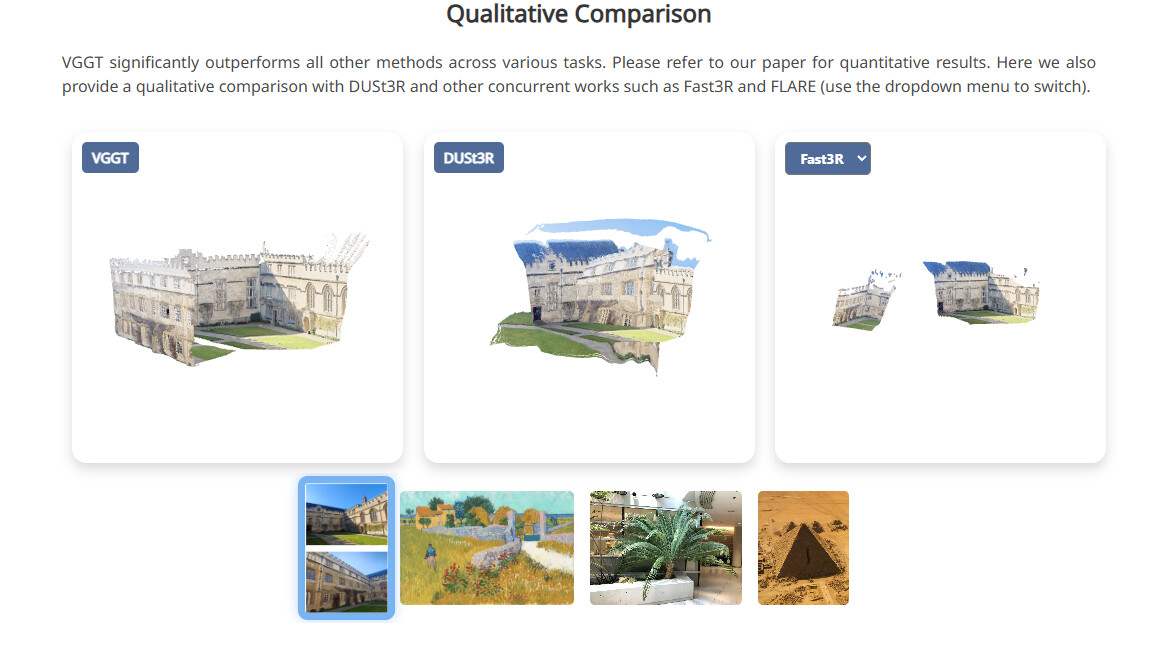
传统的三维视觉(如Structure-from-Motion、Multi-view Stereo)方法严重依赖几何优化(如Bundle Adjustment),不仅计算复杂、时间消耗大,还难以端到端训练。来自 Meta AI 的 VGGT(Visual Geometry Grounded Transformer)斩获 CVPR 2025 最佳论文奖。这项工作提出了一种通用、前馈式的 Transformer 架构,能同时从单张或多张图像中预测相机位姿、深度、点云等三维信息,无需 BA(Bundle Adjustment)、SfM 或外部优化。
 总结这篇工作的几个要点:
总结这篇工作的几个要点:
- 统一视几何建模框架:无需多阶段流程或后处理,VGGT 前馈结构即可完成 dense geometry 感知。
 极高推理效率:几秒内处理几百张图像,适合实时/大规模场景重建任务。
极高推理效率:几秒内处理几百张图像,适合实时/大规模场景重建任务。 支持多任务输出:相机姿态、深度图、稠密点云、体素、mesh,甚至全景图像一致性跟踪。
支持多任务输出:相机姿态、深度图、稠密点云、体素、mesh,甚至全景图像一致性跟踪。 Transformer 架构对计算神经科学启发:引入视觉记忆机制与 token 内几何关系建模,或可类比人类视觉系统中的空间定位机制(如海马体位置编码)。
Transformer 架构对计算神经科学启发:引入视觉记忆机制与 token 内几何关系建模,或可类比人类视觉系统中的空间定位机制(如海马体位置编码)。
 演示与代码:
演示与代码:
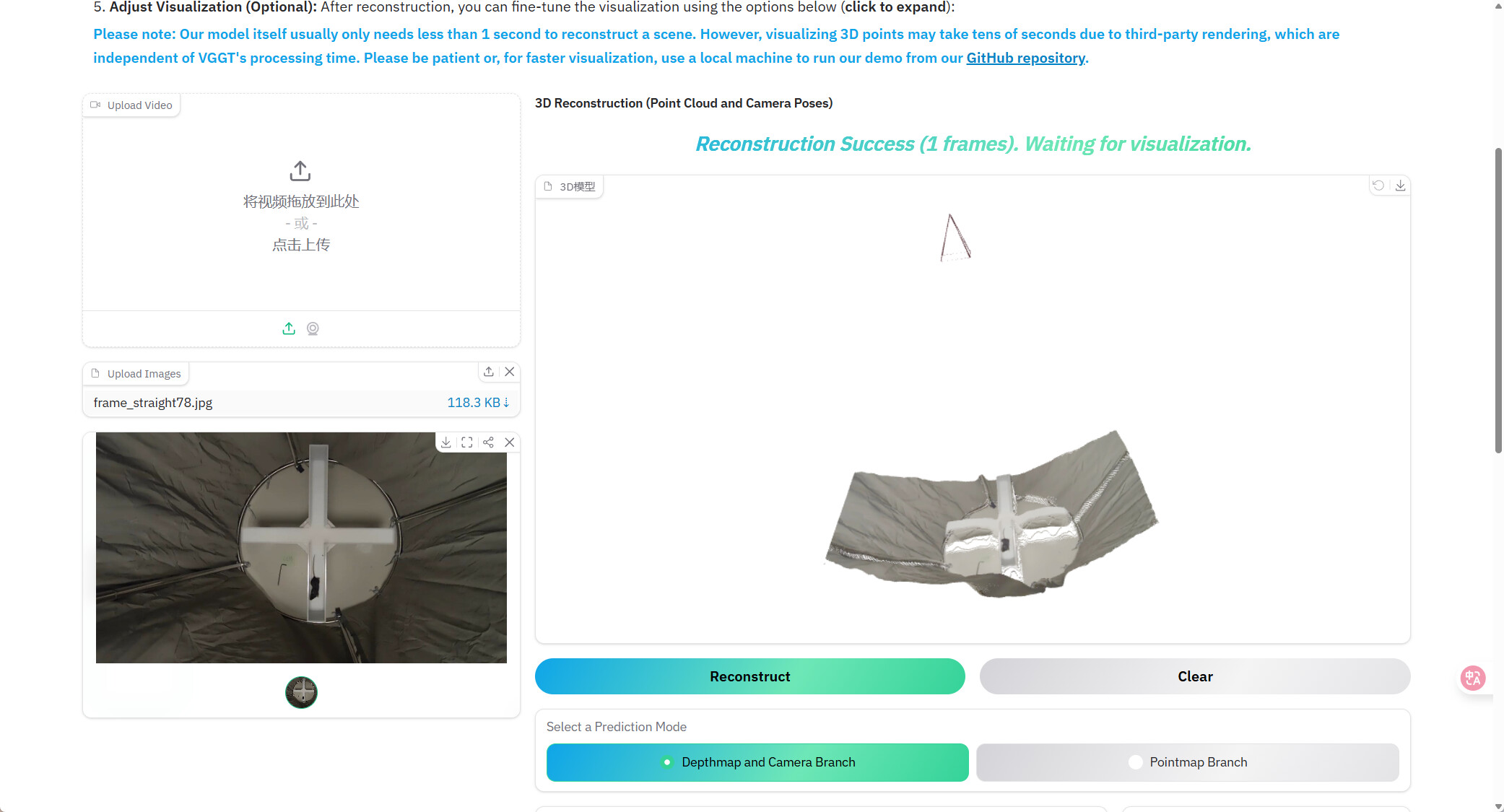
不得不说代码简洁,推理速度极快,而且交互体验很好。笔者实测在3090上能轻松运行
只需上传图片序列,即可快速生成相机轨迹与三维结构。这里给出一个十字高架桥的例子,可以看到,重建效果还是非常好的。不过其训练数据不可能覆盖所有实验范式,目前训练代码还未公布。待其公布后,笔者会第一时间尝试运行,再和大家分享。