RAG 检索模块到底在干嘛?
简单来说,RAG 是“先检索,再生成”: 用户提问后,系统先去知识库里找资料(Retrieval),再让大模型基于资料生成回答(Generation)。
从测试视角看,这个过程最容易出问题的地方有三处:
-
检索不准(答非所问)
-
检索不全(漏掉关键信息)
-
检索太慢(性能瓶颈)
所以检索模块优化的目标是三件事:提质、降噪、提速。从以下角度看RAG检索模块优化的方向
embedding质量
-
构建一组标准问答集(golden set);
-
计算不同模型的 Top-K 命中率、Recall@K、MRR;
-
输出自动对比报告。
建立“评测基线(Baseline Evaluation)” 固定一组模型 + chunk 策略 + 索引配置作为基线组合, 每次升级 embedding 模型或数据库参数,都与基线自动对比,只有各指标全面提升才允许替换。
分块策略
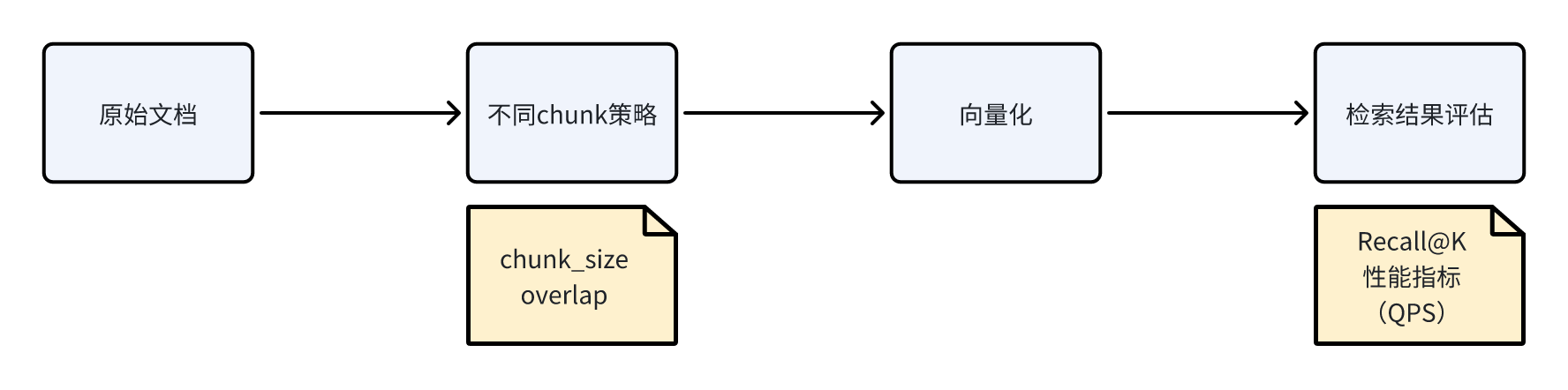
Chunk(文档切分)太小会导致语义碎片化,太大又容易召回噪声。 测试优化可通过参数扫描找到最佳平衡点:
chunk size = [200, 400, 600, 800],overlap = [0%, 10%, 20%] 自动评估 Recall@K 和性能曲线。
混合检索
-
融合排序算法是否合理;
-
去重逻辑是否可靠;
-
Hybrid 模式是否拖慢响应。
使用混合对照实验,查看性能
文档更新
知识库验证流程:
-
新文档能否被命中;
-
删除替换后旧索引是否清理;
-
索引更新是否影响性能;
-
检索结果是否出现“漂移”